Confusing books.
So I worked on this silly project called "Confusing books" at the databit.me festival in October 2015 in Arles (which was overall about digital books).
This is the post-mortem.

The main idea was to extract grammatical structures out of a book, reuse them using lexicon from another book, then print a number of copies of unique books.
Here is how it is ideally supposed to work :
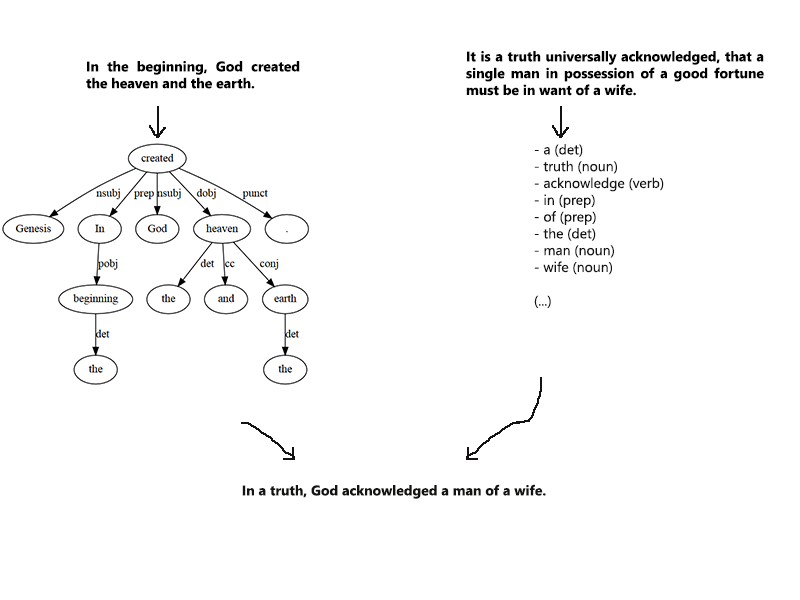
I know I'm supposed to go to hell for playing with holy writ, but let's hope the results are worth it.
One of my first attempt at generating text this way during the week was to build a gorgeous XML database of accepted grammatical structures starting from simple/complex/compound sentence and subdividing them recursively all the way down to noun/verb/adjective/punctuation/etc.
I was then using RiTa/Wordnet to put actual words on it and have fun with semantic relationships.
While this was starting to look pretty cool, I quickly realized that the task would take a lot more than one week to complete, especially because of the word dependencies (which can get pretty wild sometimes) problem.
For some reason I had trouble loading the RiTa lexicon, so if anyone encounters the same problem, my temporary solution was to hack it into this file : rita_dict.txt, and load it this way :
RiLexicon lexicon = new RiLexicon();
String[] txtDic = loadStrings(dataPath("rita_dict.txt"));
for (String w : txtDic) {
String[] wp = w.split("%");
lexicon.addWord(wp[0], wp[1], wp[2]);
}
So in order to have some funny results by the end of the week I switched to another solution : the textRazor API.
It is a neat php thing that analyzes texts for you, the part I'm concerned with is of course the "words" tab.
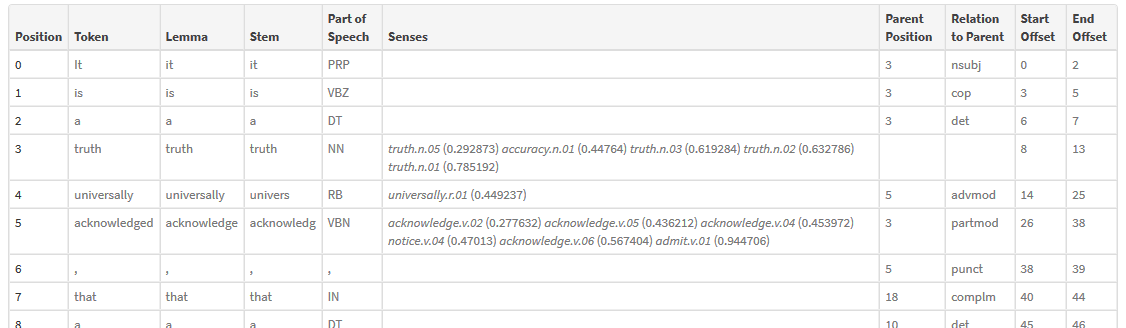
It uses the Penn Treebank part-of-speech tags.
I'm using it to generate .json files and then load it into Processing.
The content of this file typically looks like this :
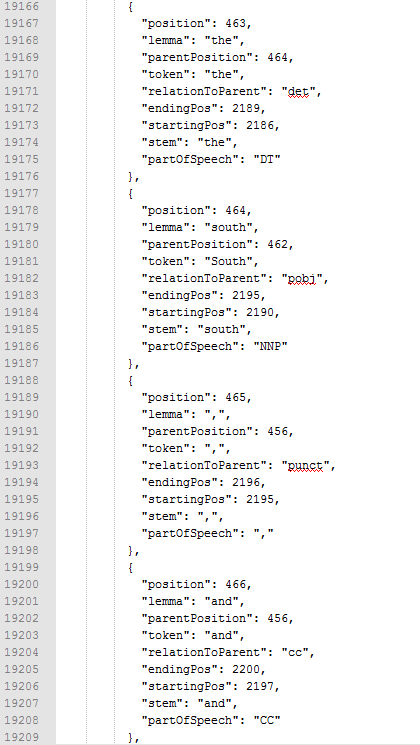
I am then loading two of them, searching for matches and replace them while keeping track of the number of uses to prevent a single word to spread all over the text.
If a word can not be found (i.e. one of the text has no proper noun in it) I'm using the original one instead (like in the God + Wuthering Heights example above).
Now, time for the sad truth about the actual results :
Here is the beginning of Franz Kafka's Metamorphosis :
One morning, when Gregor Samsa woke from troubled dreams, he found himself transformed in his bed into a horrible vermin.
Now a few words from Herman Melville's Moby Dick :
Call me Ishmael. Some years ago--never mind how long precisely--having little or no money in my purse, and nothing particular to interest me on shore, I thought I would sail about a little and see the watery part of the world.
And here is what the software thinks Franz Kafka's Moby Dick would be like :
Ten mind, how Ishmael November thought in belted years, me knew me washed on my money about some ago--never purse.
As we can see, this simple text exposes its batch of problems that would need to be fixed in a potential future update :
- Pronouns are probably the most common source of problems and using them without any further subdivision (personal, reflexive, possessive, etc) is definitely not enough.
- Due to either bad source or bad parsing the dashes in "ago--never" are turning them into a single word, and textRazor for some reason thinks it's an adjective...
- Even though there are ten of them, "mind" keep being singular (numbers including "one" is a very special case here). That could probably be fixed by browsing dependencies and bringing back RiTa into play.
There are many questionable choices in the algorithm as it is now, such as replacing the punctuation or using alternate names for a single characters.
Actually, due to the many peculiarities of English language, it is quite rare to find actually correct grammar and somewhat semantically correct sentences in the final text.
I know it could still be greatly improved with a lot of trials, errors and corrections.
Note that it's pretty common to read resulting sentences that for some reason do not seem to be correct but are actually very twisted structures that become difficult to unknit once random words are thrown into them, that's another reason why I choose to call them "confusing".

I downloaded some of the most popular books on Project Gutenberg, then trimmed them to about 20000 characters, cleaned up carriage returns and such.
Then I asked the software to produce every hybrid combination out of them and lay them on a A4 piece of paper so that it could be folded, cut, clipped, and turned into tiny books.


I like working with all the analysis/lexicon tools mentioned above, one of my long-term goal would be to help providing good equivalents for the French (which is my native language).
I'll put an end to this page with a random thought of the day :
All these torture tools I'm using on words are, as far as I know, part of a field of study called "natural language processing".
I realized recently that the acronym NLP also stands for "neuro-linguistic programming" which is, in some way, opposite...
One is about speaking to computers as if they were humans and the other is for speaking to humans as if they were computers.
Anything to say ? -> 
cheers